Accelerating AI adoption
Solution accelerators are pre-built, open-source solutions designed to accelerate proof of value. They provide a starting point for the most common scenarios and are adaptable to partners' and customers' business needs. The Gold Standard Accelerators built by our team incorporate quality of life features like quick deploy instructions, use case starting points, cost summaries, architecture diagrams, and comprehensive documentation to help get customers started.
The Challenge
Analysts and data operations teams face a major challenge in extracting usable, structured information from documents spread across formats, systems, and workflows. Manual data cleaning and cross-referencing are time-consuming, error-prone, and often disconnected from a traceable system of record.
The goal was to utilize AI to help automate the content ingestion process, mapping provided information to specified schemas, and freeing data analysts from the tedious task of data entry and cleaning, to focus on the more important work of analysis and insight generation.

My Role
I led the design of this end-to-end experience, shaping the flow from content ingestion through schema transformation and human verification, while also defining the proxy use case that supports the data necessary to generate context and comprehension.
My tasks:
1. Defined the sample use case and persona, grounding the product in real-world scenarios and AI-human collaboration.
2. Created a modular UX flow including highlighting features and capabilities addressing all defined customer challenges
3. Crafted UI states for ingestion, schema mapping, scoring, review, and JSON editing
4. Directed how the platform was packaged and deployed through Azure templates and GitHub, balancing flexibility and usability for IT teams

The approach
This project was carried out in 4 milestone stages focused on definition, design, build, and delivery. I was responsible for leading 3 of the 4 stages.
Product Definition
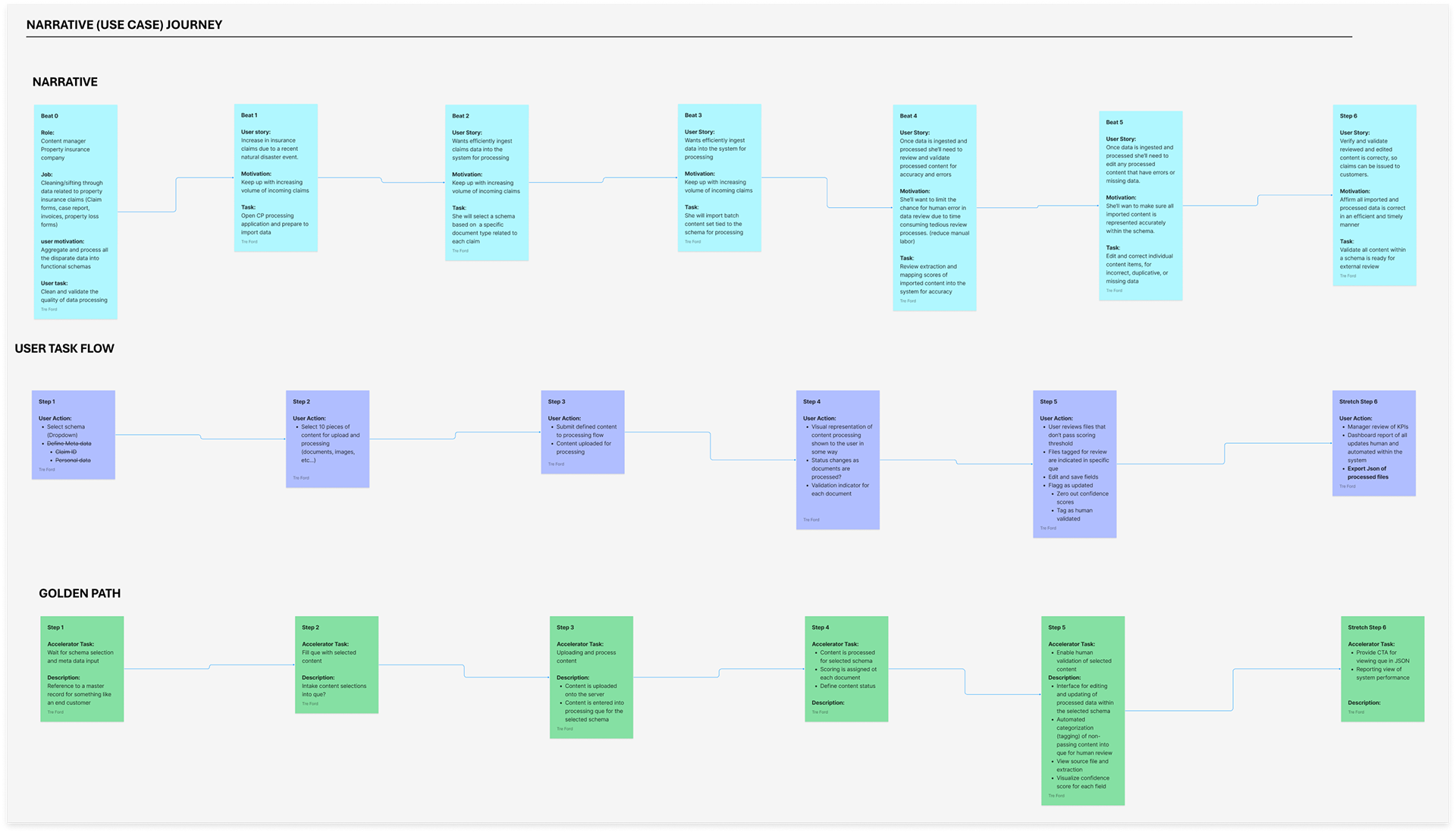
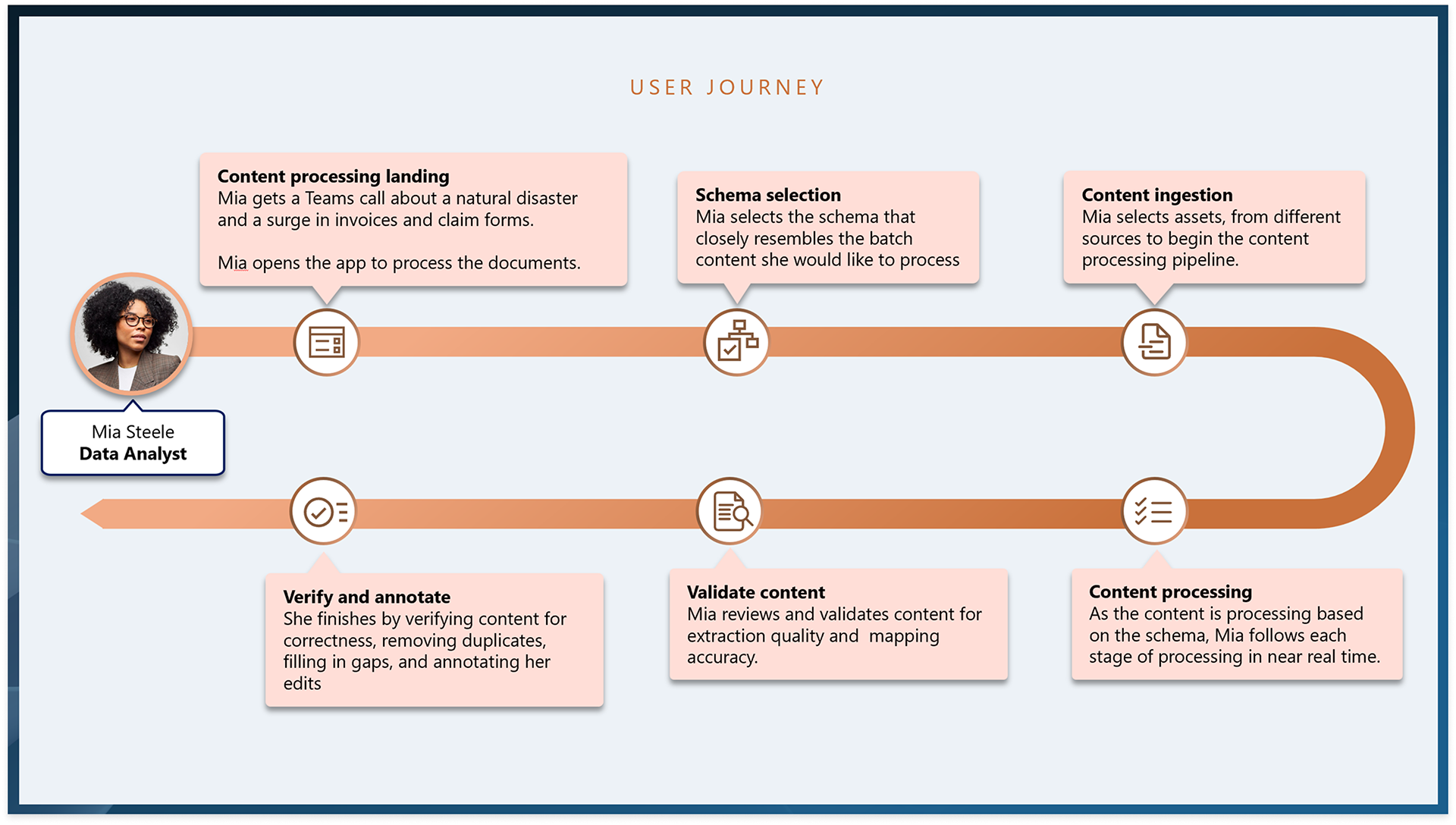
To ensure the platform met real-world enterprise needs, I led the development of a detailed use case scenario and user persona centered around Mia, a data analyst managing high-volume, multi-modal claims data. By mapping her challenges such as manual review bottlenecks, schema inconsistencies, and data confidence issues, directly to system capabilities, we validated and shaped key features like confidence scoring, schema-based data transformation, audit trails, and human-in-the-loop verification tools.


The approach
This project was carried out in 4 milestone stages focused on definition, design, build, and delivery. I was responsible for leading 3 of the 4 stages.
Design Exploration
The design focused on simplifying complex, multi-stage workflows into a clear and intuitive experience, enabling users to ingest, process, and validate unstructured content with confidence.
Target objectives
1. Simplify complex workflows across ingestion, transformation, and review into a clear, modular interface
2. Support real-time visibility into processing status and flag issues where user attention is needed
3. Build trust in AI systems through transparent confidence scoring and human-in-the-loop correction tools
4. Design reusable templates that guide users through schema selection and validation
5. Create intuitive entry points for both technical and non-technical users, including analysts, developers, and auditors
First iteration
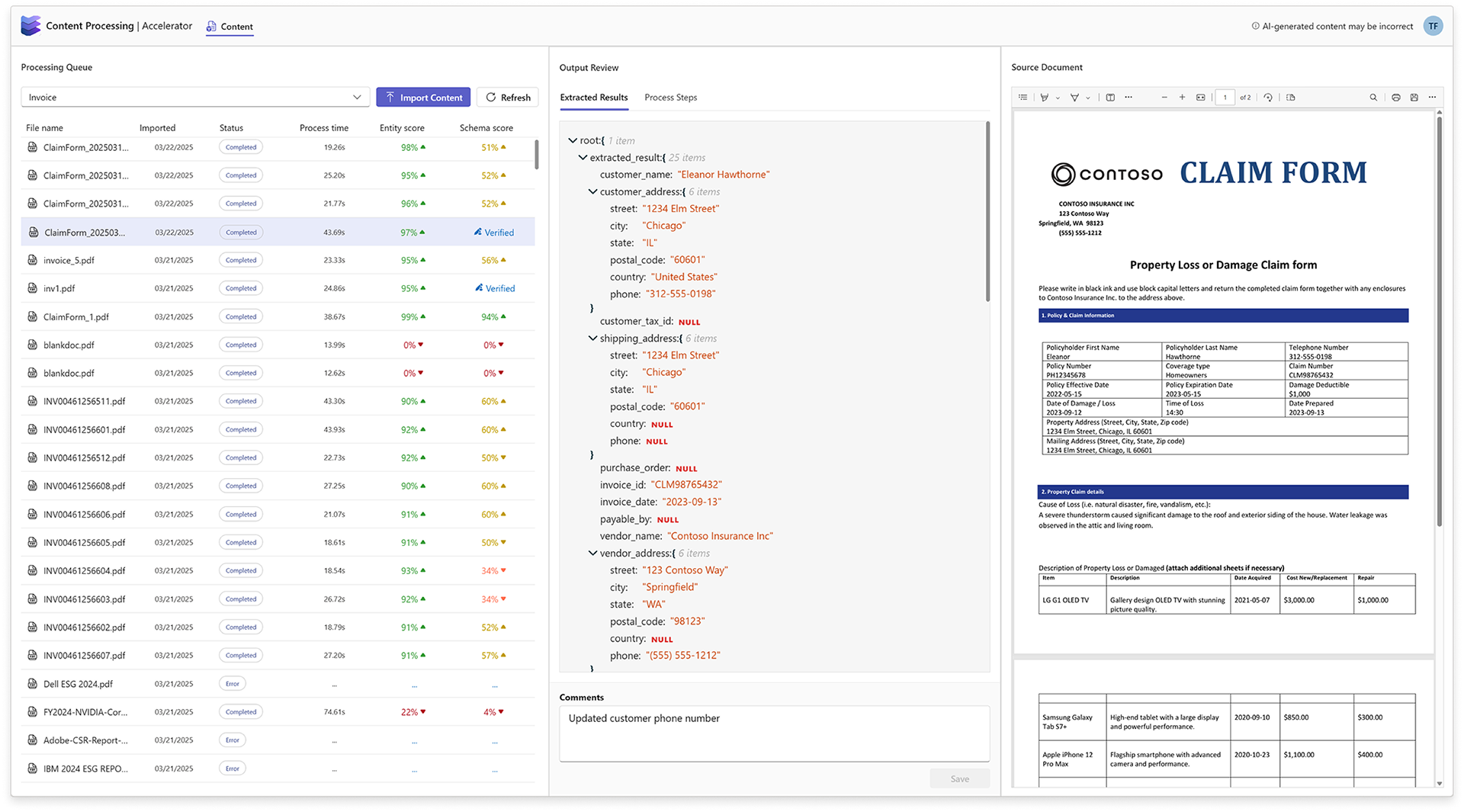
My first iteration explored how a user might ingest a dataset, track its progress, then see at-a-glance the quality of the schema mapping performance. From there, how would the user then edit validate the results for use by stakeholders and clients.
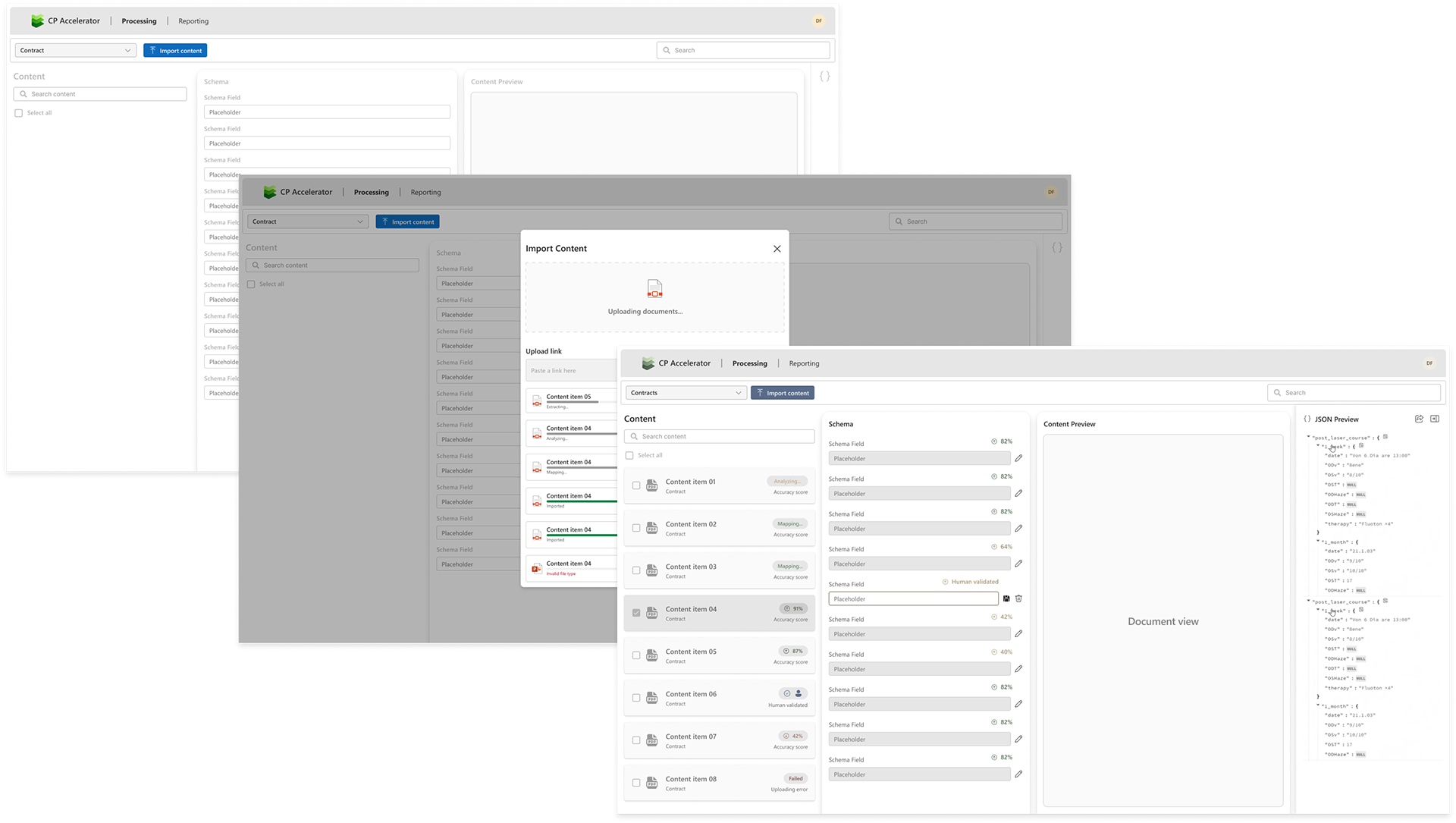
Second iteration
My second iteration imagined an interactive UI for editing schema discrepancies that the automated system failed to parse. Along with a robust JSON viewer, users could easily see where the system had failed and make the necessary adjustment.
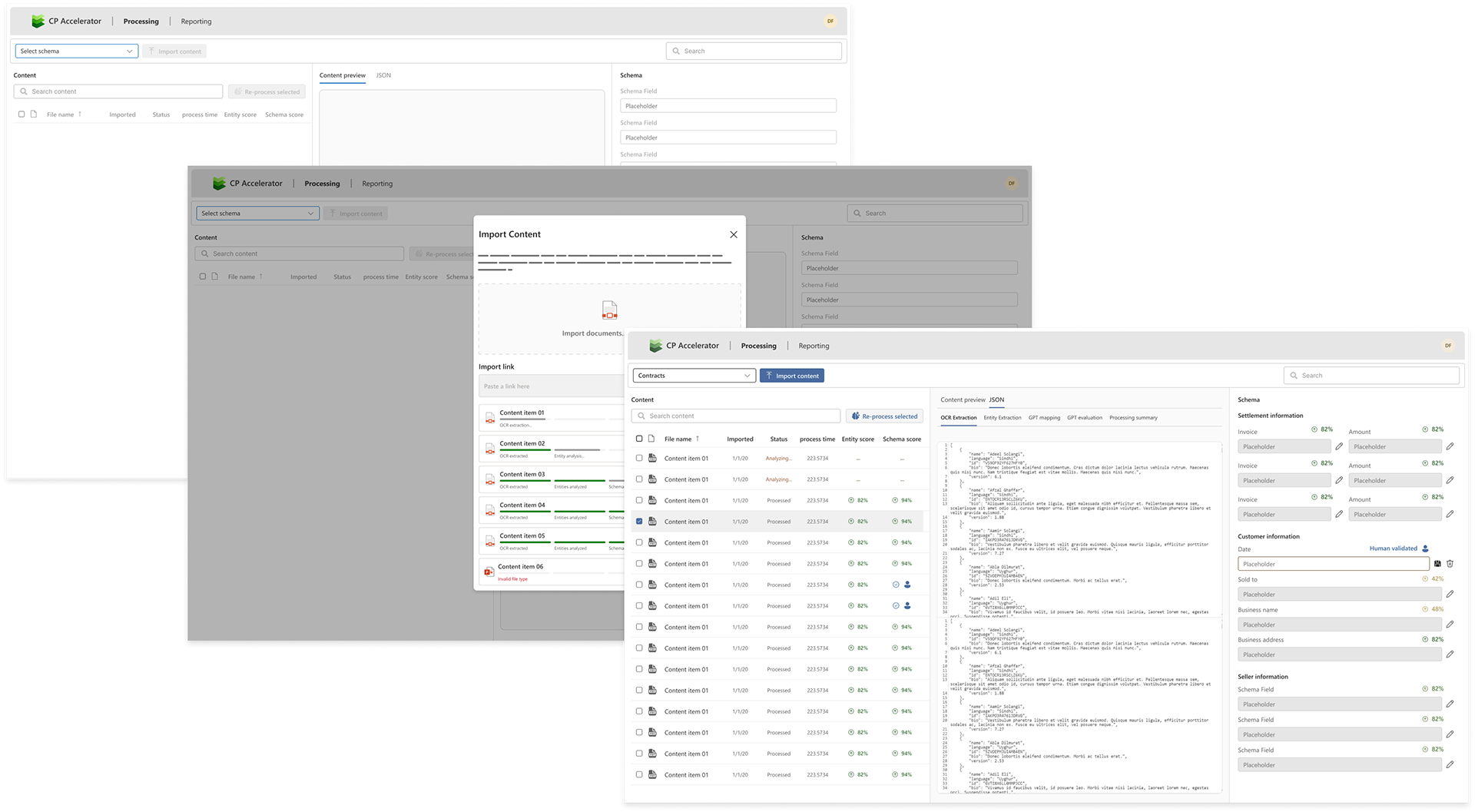
Final iteration
My final iteration didn't integrate the interactive UI due to development complexity but did incorporate the schema selector, a JSON editor for making data adjustments, a comment box allowing for simple flagging of manual data changes, and a document viewer provided an always accessible reference for cross checking ingestion results.
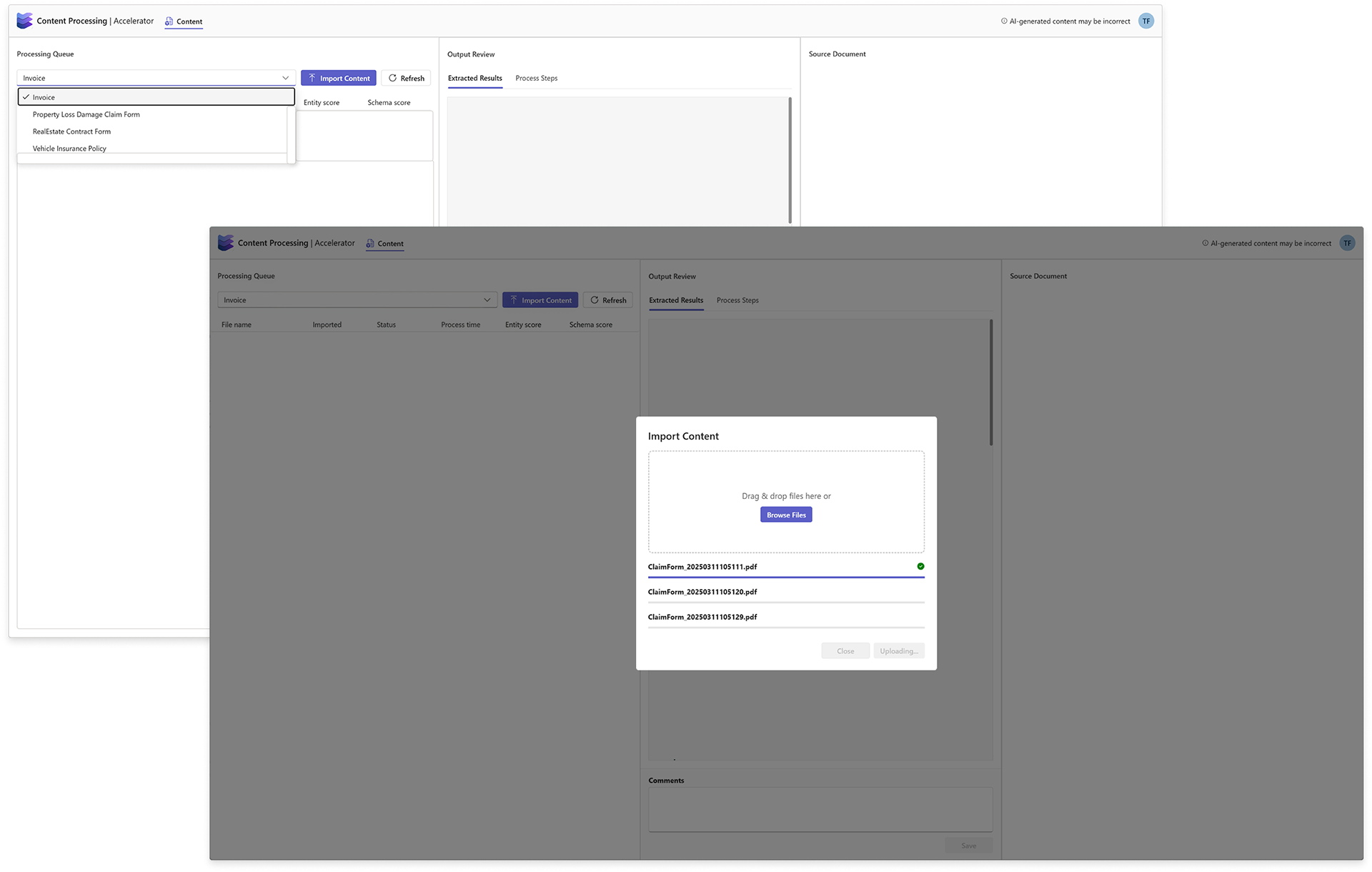
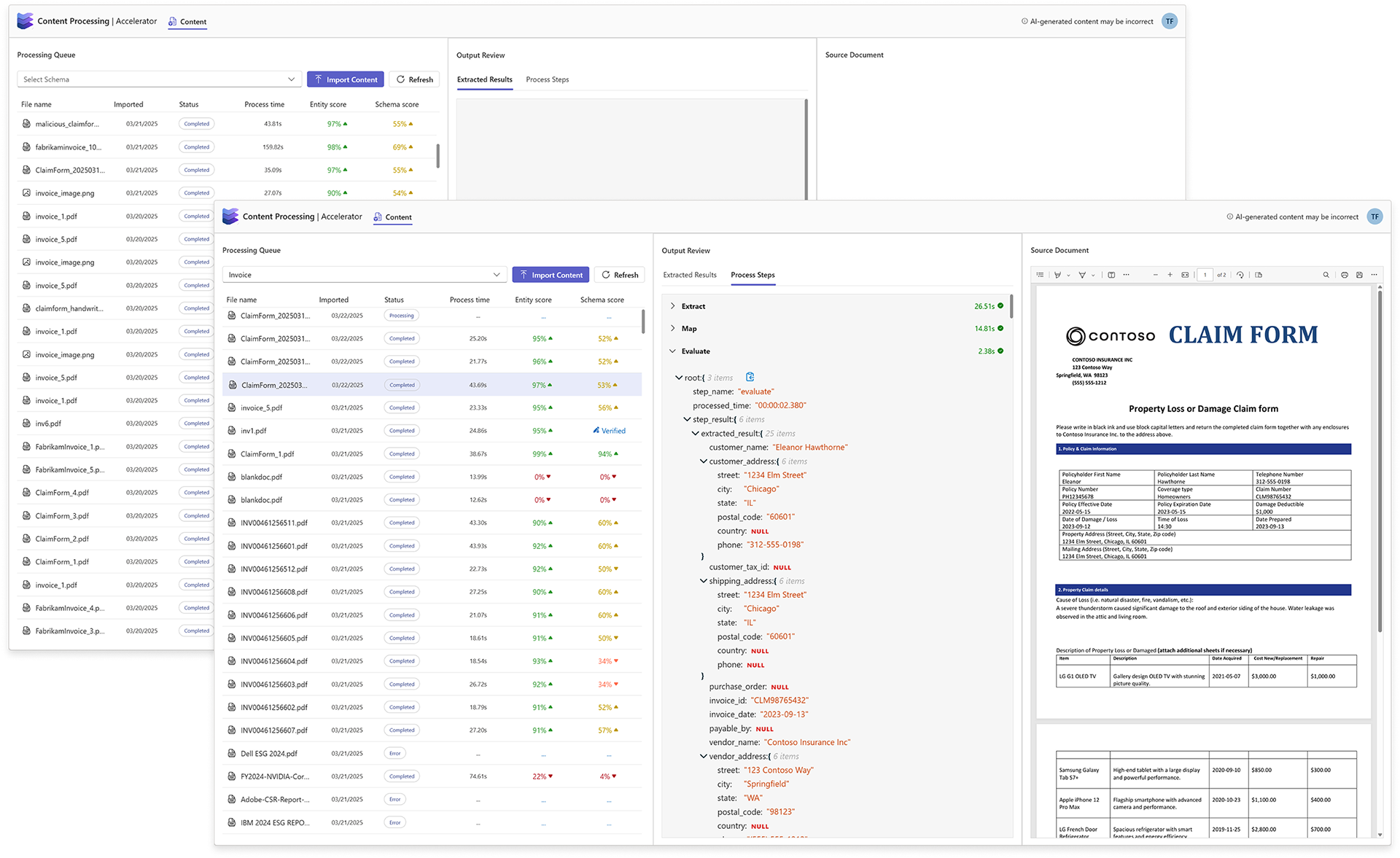

The approach
This project was carried out in 4 milestone stages focused on definition, design, build, and delivery. I was responsible for leading 3 of the 4 stages.
Packaging Objectives
Once the design was handed over for development we needed to prep the product for delivery to our customers. That included information design for the technical architecture, GitHub layout design for easy access and use by customers, as well as presentation design to help our sellers communicate value to their customers.
Technical Features
1. Support programmatic ingestion and event-based workflows via Azure Logic Apps, Container Apps, and APIs
3. Enable schema mapping and editing using customizable templates and JSON schema logic
4. Include confidence scoring at the field and schema level to trigger reviews based on AI reliability thresholds
5. Automate deployment and scalability with Azure Bicep templates, preflight quota checks, and modular components
6. Log and monitor pipeline activity to ensure traceability and operational transparency for enterprise compliance needs
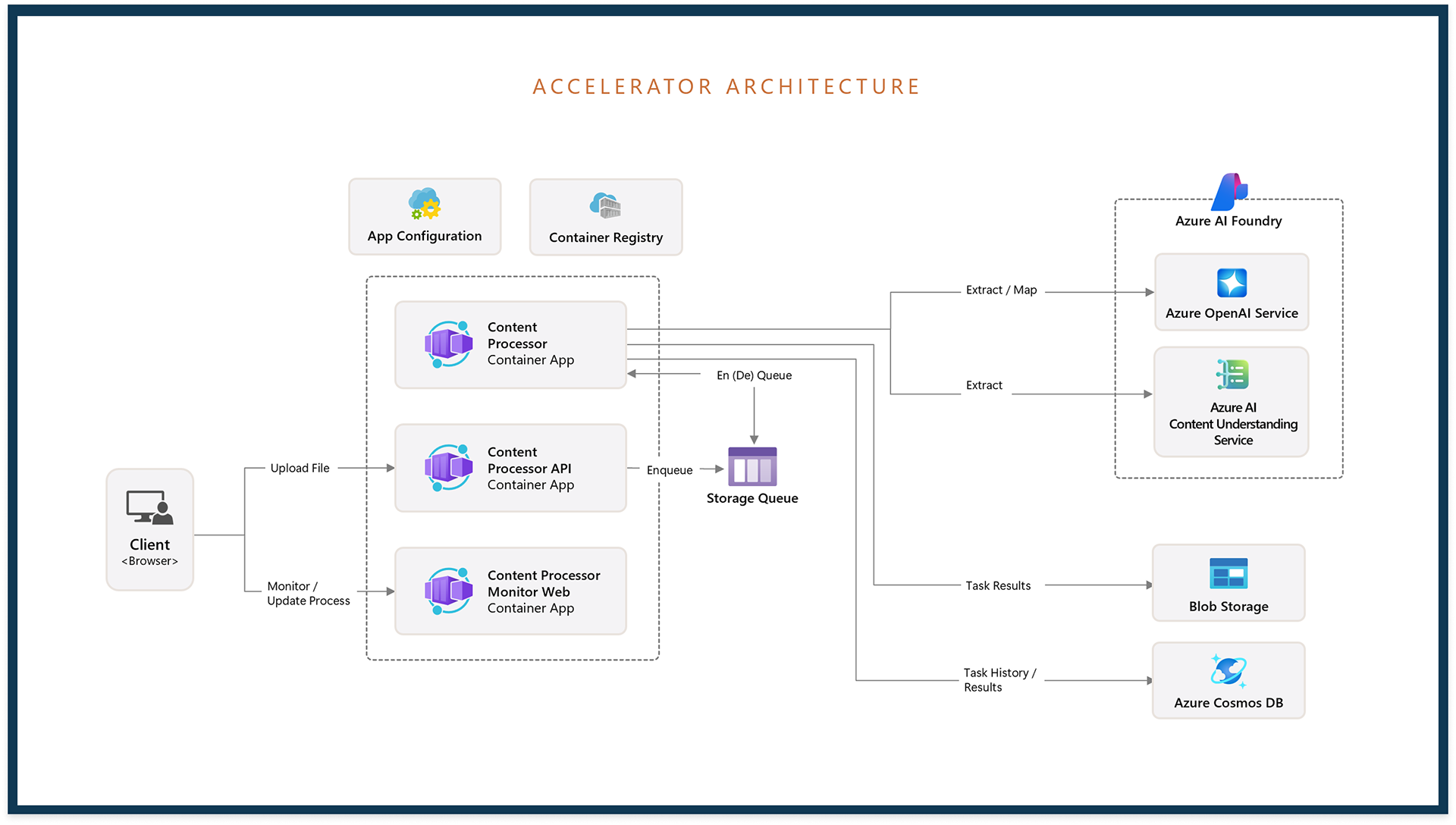
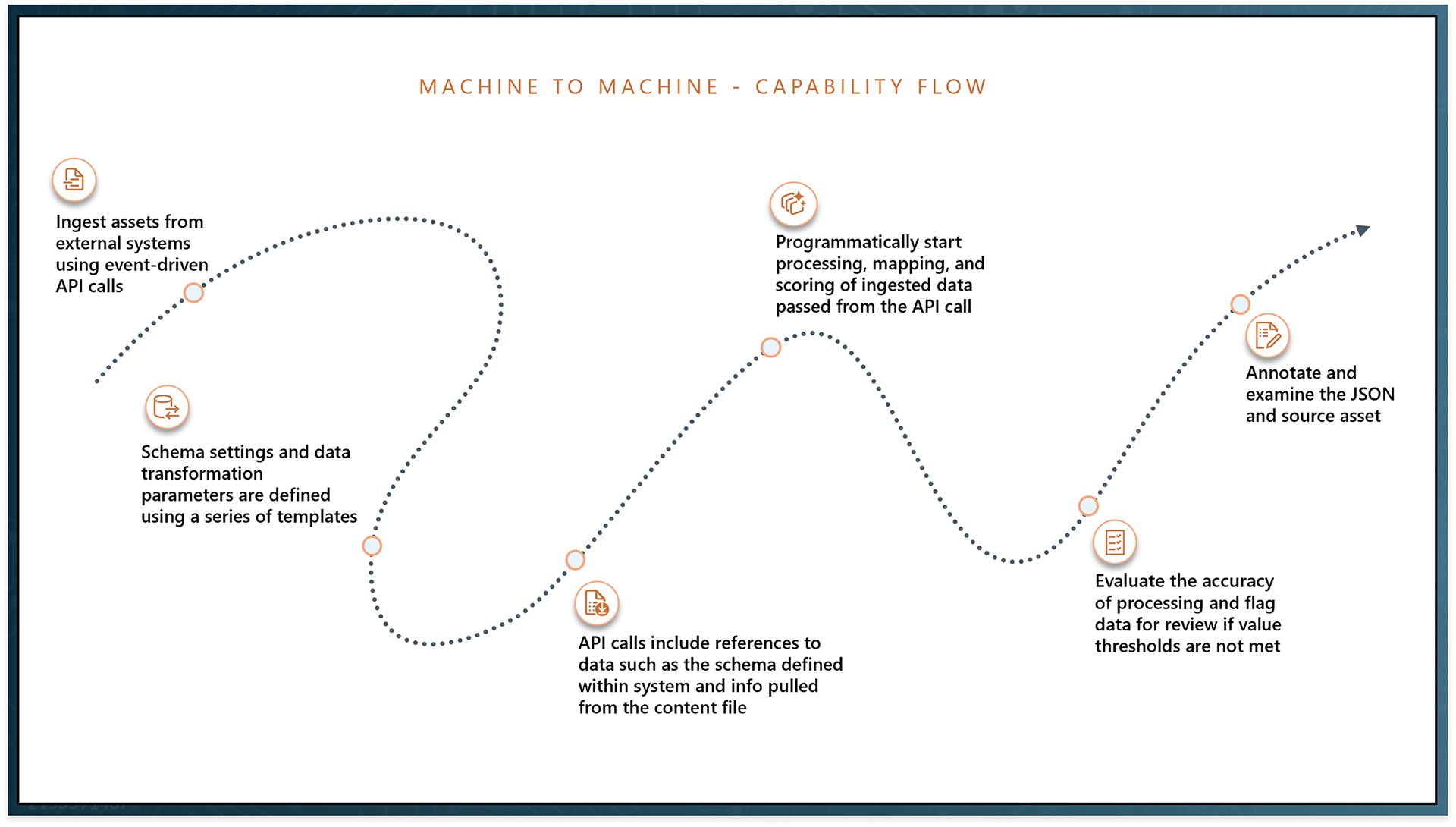
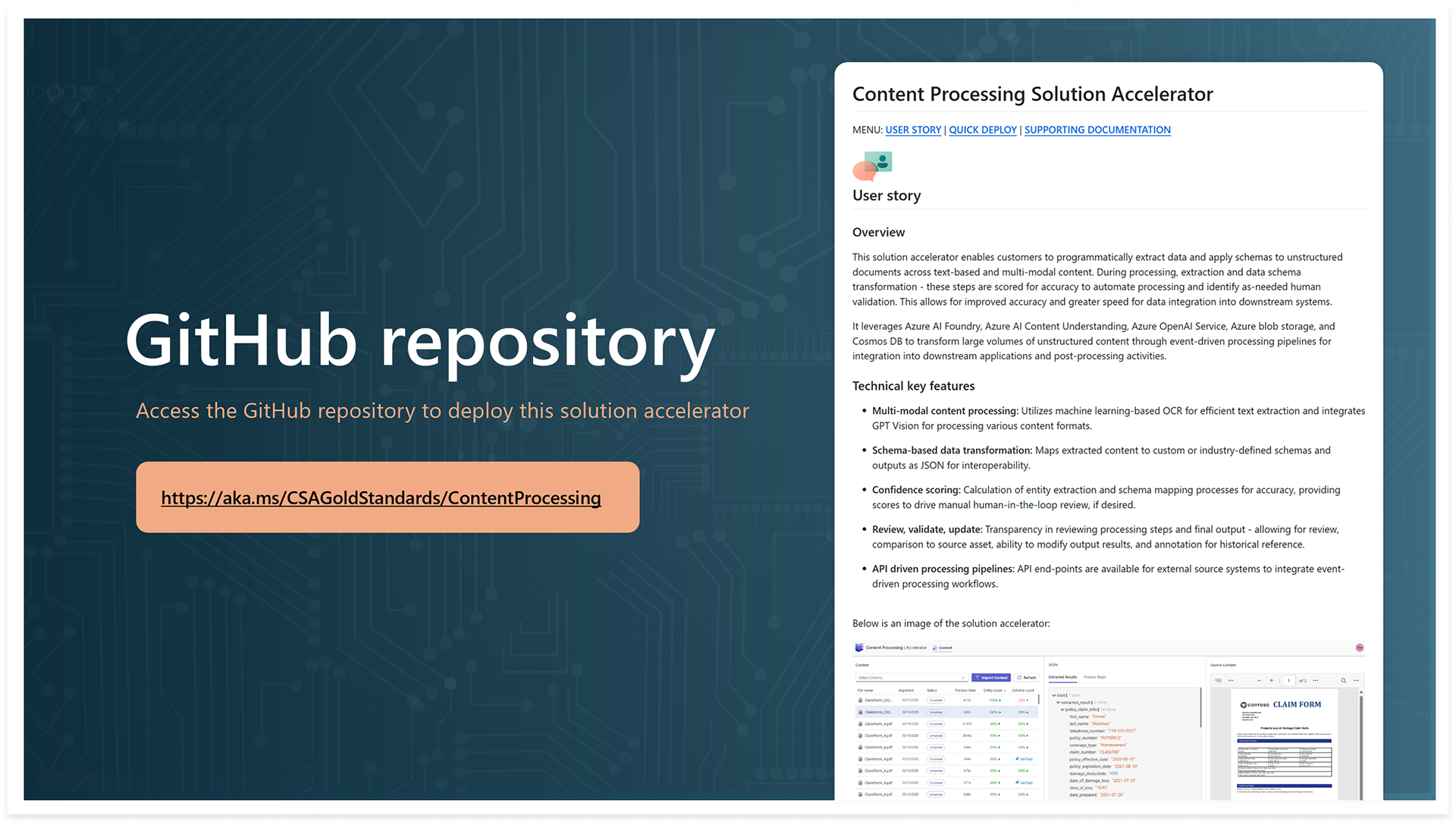
GitHub repository
The GitHub repository was the perhaps the most crucial step in creating a product that was accessible to a varied audience. It needed to introduce and summarize the product, communicate value customer stakeholders, and enable deployment by their technical specialists. You can view the live repository for this accelerator at the link below.